Roc And Shay Wikipedia - Getting A Grip On Performance
When you hear a name like "ROC," you might find yourself wondering what it really means, or perhaps, like your search for "roc and shay wikipedia," you're looking for clarity on something specific. It's really quite common to come across terms that seem to have many layers, so it's almost natural to seek out plain explanations for them. Today, we're going to unpack a concept that, while perhaps not what you initially thought of, is actually quite important in the world of data and how we measure things.
So, we're talking about a tool that helps us see how well something performs, particularly when we're trying to sort things into different groups. It has a rather long official name, but people usually just call it "ROC" for short. This method gives us a clear picture of how good our predictions are, which is pretty useful in lots of different areas, especially when working with information systems that try to make smart guesses.
This particular "ROC" concept, as a matter of fact, helps us get a handle on how reliable our sorting efforts are. It shows us, in a very visual way, how often we get things right compared to how often we might make a mistake. It’s a way to really look at the strengths and weaknesses of a system that tries to tell one thing from another, giving us a solid basis for judging its effectiveness.
Table of Contents
- What's the Big Deal with ROC?
- Drawing the Picture - How ROC Works in the Context of "roc and shay wikipedia"
- Why Do We Care About ROC and AUC?
- Is the ROC Curve Always Smooth, or What's the Deal with "roc and shay wikipedia" and Jagged Lines?
- Real-World Puzzles - Making Sense of "roc and shay wikipedia" Performance
- Practical Tips for Understanding "roc and shay wikipedia" Performance
- Beyond the Basics - What Else Helps with "roc and shay wikipedia" Evaluation?
- Summing It Up
What's the Big Deal with ROC?
When people talk about "ROC," they're usually referring to something called the Receiver Operating Characteristic Curve. It's a way, you know, to look at how well a system or a test can tell the difference between two groups, like whether someone has a certain condition or not, or if an email is spam or not. It's a visual tool, which is quite helpful for getting a quick sense of things.
This curve, in fact, helps us see how effective a particular measure is across its various possible settings. It lets us, as it were, observe the trade-offs involved when you try to make something more sensitive to picking up what you want, while also trying to avoid picking up what you don't want. It’s a very practical way to assess how well a test performs in different situations, giving you a comprehensive view of its capabilities.
Basically, this curve shows us how good a method is at distinguishing between positive and negative outcomes. It's a picture, if you will, that helps us understand the effectiveness of a prediction model. For example, in machine learning, where computers learn to make guesses, the ROC curve is a really important way to figure out how well those guesses actually turn out. It's a bit like checking the accuracy of a weather forecast, but for data systems, so it's almost always a good idea to look at it.
Drawing the Picture - How ROC Works in the Context of "roc and shay wikipedia"
So, how do you actually draw one of these "ROC" curves? Well, it's put together by plotting two main things against each other. On one side, going up and down, you have what's called "sensitivity," which is sometimes known as the "true positive rate." This tells you how good your system is at correctly identifying the positive cases, which is really what you want to see.
Then, on the other side, going left to right, you plot "one minus specificity," which is also called the "false positive rate." This shows you, in a way, how often your system incorrectly identifies something as positive when it's actually negative. The goal, of course, is to have a system that's very good at finding the positives without too many false alarms, so it's almost always a balance you're looking for.
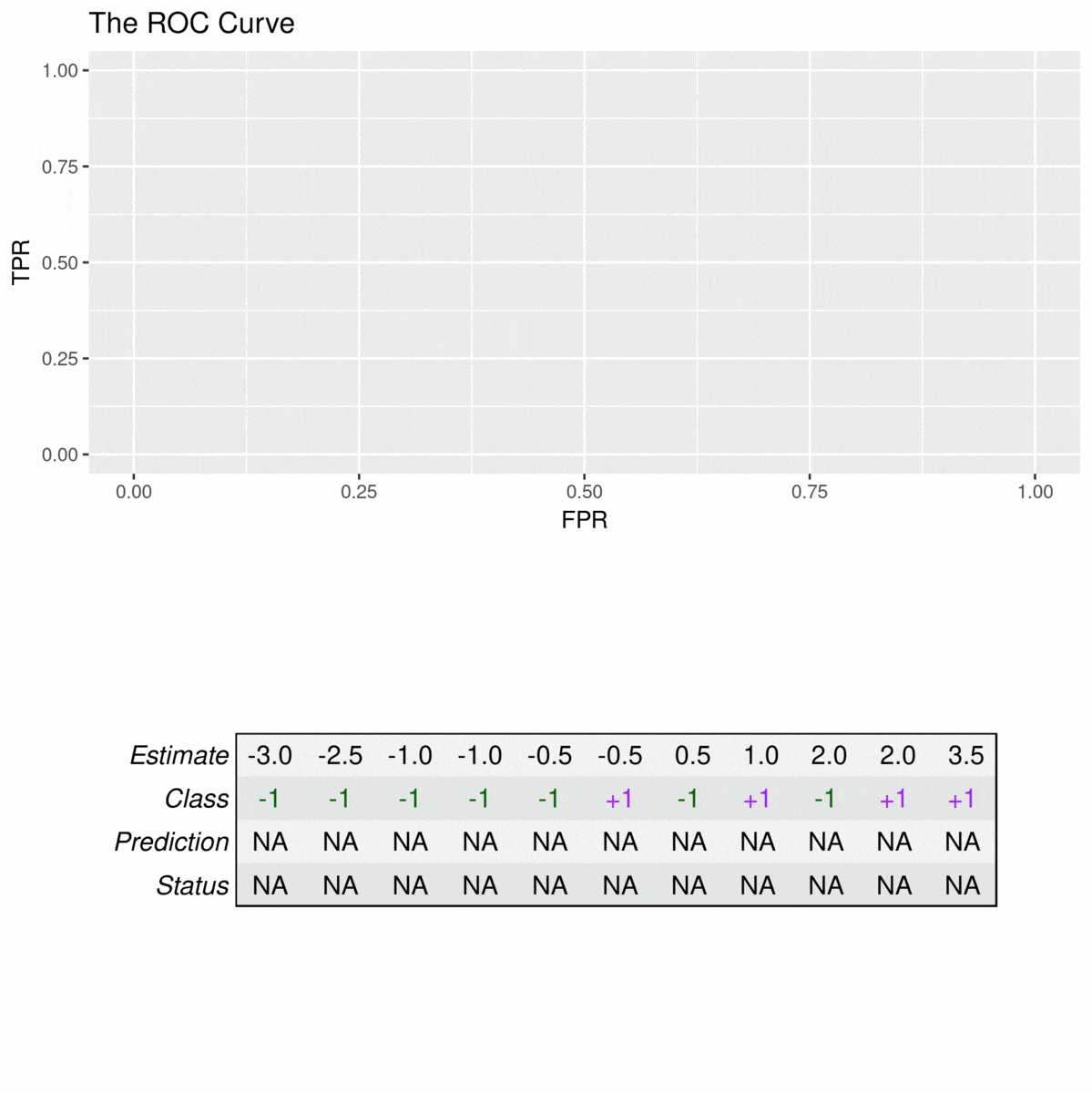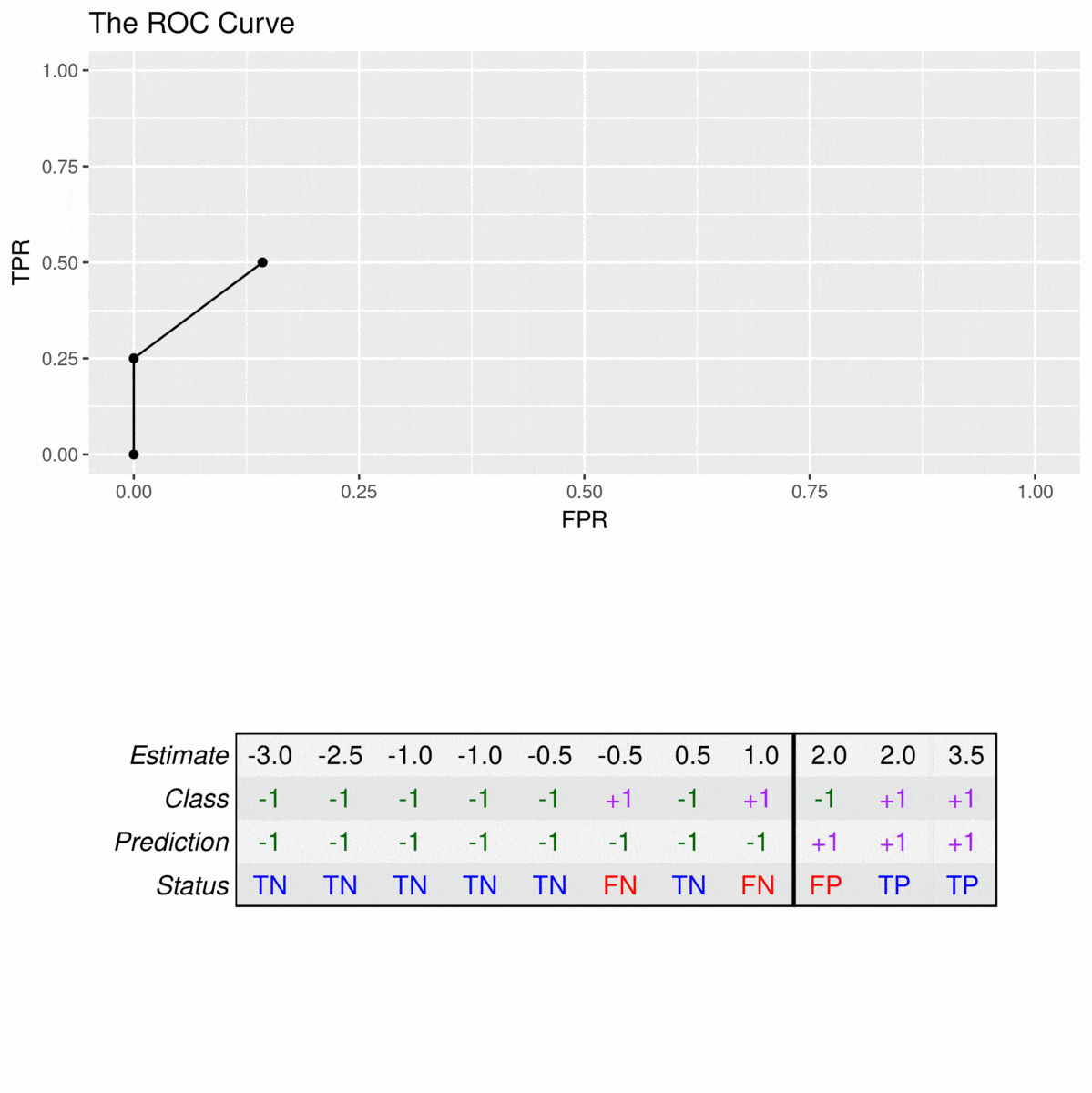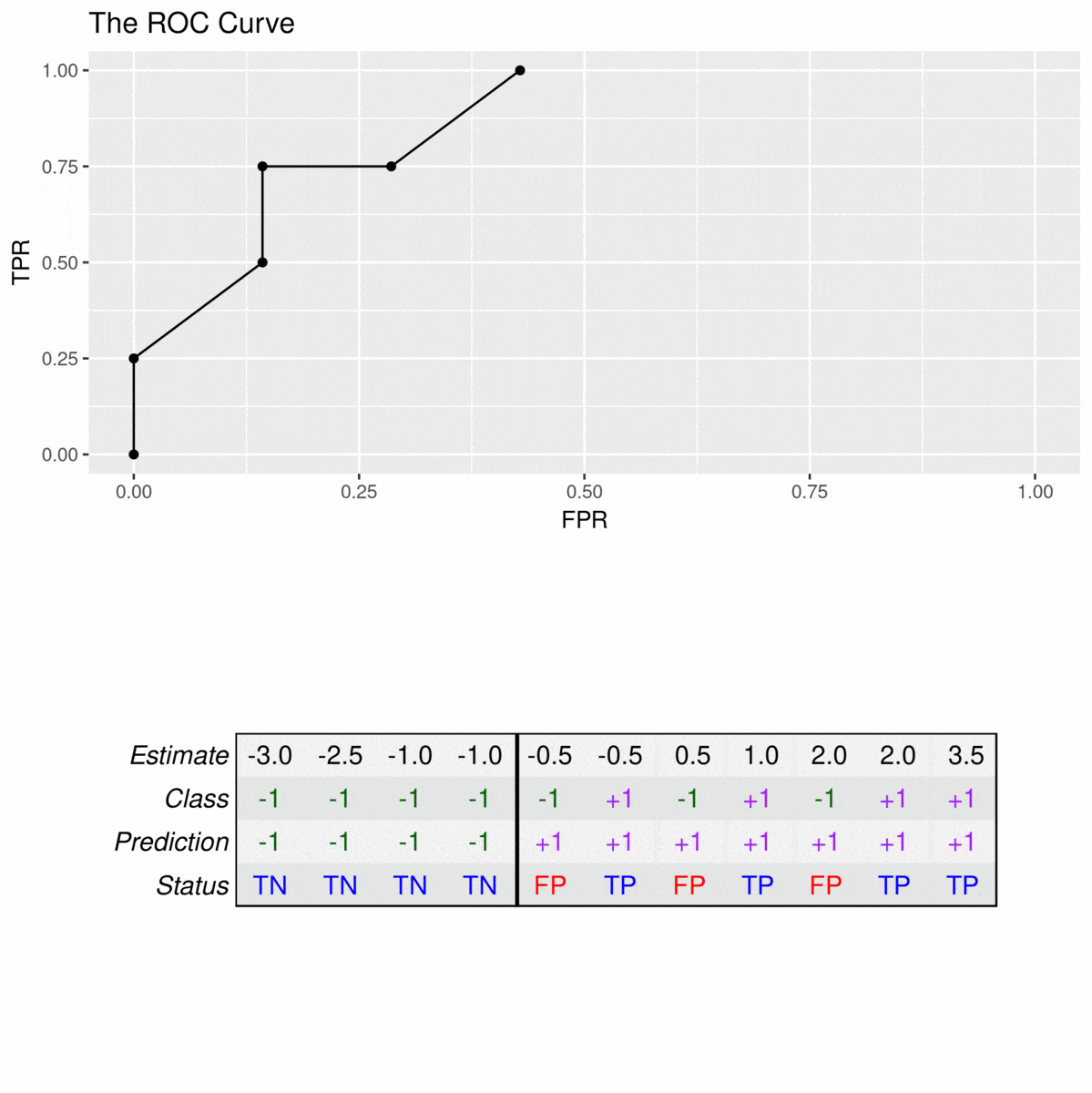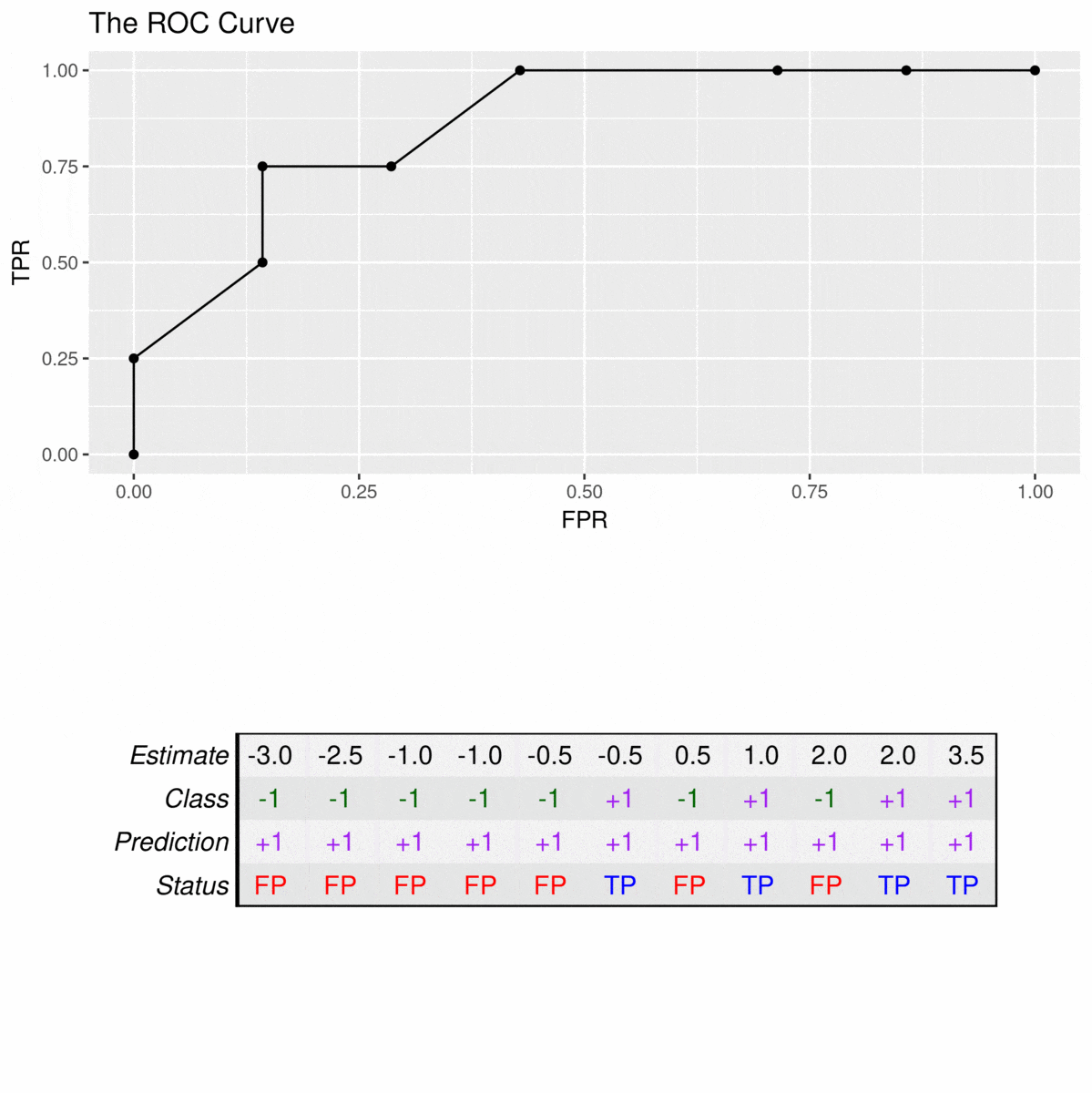
By drawing this curve, you can, in fact, get a clear visual of how well a particular indicator or a prediction model performs across its different settings. Each point on the curve represents a different threshold for making a decision, and you can see how changing that threshold affects both the true positive rate and the false positive rate. This helps you pick the best spot for your specific needs, which is pretty neat for anyone trying to get a handle on "roc and shay wikipedia" related performance.
When it comes to putting these curves together, some folks use special computer programs like SPSS or Origin. These tools can help you take your data and automatically create the visual representation, making it much easier to see the relationships we've been talking about. It takes away some of the manual work, allowing you to focus more on what the curve is telling you, which is very helpful, you know, for practical purposes.
Why Do We Care About ROC and AUC?
Now, you might be asking, "Why is this ROC thing so important?" Well, in the world of machine learning, where we build computer programs that learn from data, the ROC curve, along with something called AUC (which stands for Area Under the Curve), are really big deals. They're like the report card for how well our learning models are doing their job, you know, when they try to sort things out.
The AUC, in particular, gives us a single number that summarizes the overall performance of the model. Think of it this way: the bigger the area under the ROC curve, the better your model is at distinguishing between the different groups. A model with a larger AUC, therefore, means it has a higher chance of correctly ranking a randomly chosen positive instance higher than a randomly chosen negative instance, which is pretty cool.
It's actually a very common topic that comes up in job interviews for positions related to data science or machine learning. People often ask about ROC and AUC because it shows you really understand how to evaluate the effectiveness of a prediction system. It's a way, you know, to show you can speak the language of performance assessment, which is quite important in this field.
Many people, however, sometimes find it a bit tricky to fully grasp these concepts, even after reading about them. It’s not that they are incredibly hard, but rather that they require a certain way of thinking about how predictions work. Once you get it, though, it clicks, and you see why these measures are so valuable for anyone dealing with data that needs to be categorized. It's almost like learning a new language, you know, it takes a bit of practice.
Is the ROC Curve Always Smooth, or What's the Deal with "roc and shay wikipedia" and Jagged Lines?
You might have seen some ROC curves that look perfectly smooth, like a gentle slope, but then others that appear a bit jagged, like a series of steps. This sometimes makes people wonder, "Why isn't it always a nice, smooth line?" It's a good question, and there's a pretty straightforward answer, especially when we're talking about practical applications, like with "roc and shay wikipedia" related data assessments.
One reason you might see a stepped or broken line is when you're using certain software tools, like the `roc_curve` function from `sklearn.metrics` in Python, particularly for binary classification tasks. In these situations, the curve is often drawn by connecting a series of points, each representing a different threshold for classifying something. Since there are only a finite number of unique thresholds that result in a change in the true or false positive rates, the curve naturally forms these steps.
It's not that the curve is "wrong" when it's jagged; it's just a reflection of how the data points are being processed and how the thresholds are being considered. For instance, if you have a limited number of distinct prediction scores, you'll only have a limited number of points to plot, which results in a staircase-like appearance. This is actually quite normal for many real-world datasets, so it's nothing to worry about.
A smooth curve, on the other hand, might imply that you have a continuous range of prediction scores, or that the curve has been interpolated to appear more fluid. Both types of curves convey the same underlying information about performance, but the stepped version is often a more direct representation of what's happening with discrete data points. So, you know, it just depends on the specific circumstances and the tools being used.
Real-World Puzzles - Making Sense of "roc and shay wikipedia" Performance
People often ask for simple examples to really get a handle on how to draw an ROC curve. It’s one thing to understand the concept, but actually creating one can feel a bit fuzzy at first. Imagine, for instance, you have a thousand items, and each one is marked as either "positive" or "negative." You've got a system that tries to guess which is which, and you want to see how well it does. You know, a practical example can make all the difference.
To draw the curve, you'd basically take your system's guesses and, for every possible cutoff point, you'd calculate how many positives it got right and how many negatives it got wrong. Then you'd plot those pairs of numbers. This way, you get to see how the system behaves across all its possible decision settings. It's a really good way to visualize the trade-offs, you know, in a very tangible sense.
Another interesting puzzle that comes up is when someone has a deep learning model that seems to be doing really well, maybe hitting 93% accuracy, but then they look at the ROC curve, and the AUC value is only around 0.7. This can be a bit confusing, because you'd expect a high accuracy to mean a great AUC, wouldn't you? It's a common situation, actually, that highlights something important about performance measures.
The thing is, accuracy and AUC measure different aspects of performance. Accuracy tells you the overall proportion of correct guesses, both positive and negative. But AUC, on the other hand, focuses on how well your model can rank positive instances above negative ones, across all possible thresholds. A high accuracy might happen if, for example, most of your items are negative, and your model is very good at identifying those negatives, but not so great at picking out the few positives. So, you know, it's not always a straightforward relationship.
Practical Tips for Understanding "roc and shay wikipedia" Performance
When you're trying to make sense of performance, especially for something like "roc and shay wikipedia" related data, it's helpful to remember that no single number tells the whole story. Accuracy is good, but it can be misleading if your groups are really unbalanced. That's where the ROC curve and AUC really shine, because they give you a more complete picture of how well your system can distinguish between things, regardless of how common each group is. It's a pretty big advantage, honestly.
If you find yourself with a high accuracy but a lower AUC, it’s a good sign to dig a little deeper. Perhaps your model is biased towards the more common group, or it's not sensitive enough to the less frequent, but still important, group. Looking at the ROC curve itself can often reveal this. If the curve stays close to the diagonal line for a long stretch, it means your model isn't doing much better than a random guess for certain thresholds, which is definitely something to look into.
Always consider what kind of mistakes are more costly for your particular situation. Is it worse to miss a positive case (a false negative), or to incorrectly flag a negative case as positive (a false positive)? The ROC curve helps you visualize these trade-offs, allowing you to choose a decision point that best suits your needs. It’s a very practical way to make informed choices, you know, about how your system should operate.
Beyond the Basics - What Else Helps with "roc and shay wikipedia" Evaluation?
While ROC curves and AUC are incredibly helpful for evaluating systems, especially those that sort things into categories, they're just one piece of the puzzle. When you're looking at the performance of something like "roc and shay wikipedia" related classification, it's often a good idea to consider other measures too. No single metric tells the complete story, and using a few different ones can give you a much richer view, which is pretty useful.
For example, you might also want to look at precision and recall. Precision tells you, in a way, how many of the items your system identified as positive were actually positive. Recall, on the other hand, tells you how many of the actual positive items your system managed to find. These two measures, when looked at together, can provide a lot of insight into specific types of errors your system might be making, which is quite insightful.
Sometimes, people also use something called an F1-score, which is a way to combine precision and recall into a single number. It's especially useful when you want to find a balance between avoiding false positives and avoiding false negatives. So, you know, depending on what's most important for your particular task, you might choose to focus on different measures, or a combination of them, to get the clearest picture of performance.
Ultimately, the goal is to choose the right tools to assess how well your system is working for its intended purpose. The ROC curve gives you a fantastic visual summary of a system's ability to distinguish between groups, and AUC offers a convenient single number for overall comparison. But combining these with other metrics allows you to really get a comprehensive grasp of performance, ensuring you're making the best decisions based on your data, which is actually what it's all about.
Summing It Up
So, we've talked about the ROC curve, which stands for Receiver Operating Characteristic Curve. It's a really useful way to see how well a system can tell the difference between two groups, by plotting how often it gets things right against how often it makes a certain type of mistake. This visual tool, along with AUC, the area under the curve, helps us judge the overall effectiveness of a prediction model, especially in areas like machine learning.
We've also touched on why these curves can sometimes look like steps rather than smooth lines, particularly when using certain software for binary classification, and how that's a perfectly normal thing. We even looked at some common questions, like why a high accuracy doesn't always mean a high AUC, showing that different measures tell us different things about performance. It's all about getting a complete picture.


Detail Author:
- Name : Jeramie Hoppe
- Username : eladio51
- Email : ojohnson@gmail.com
- Birthdate : 2000-11-01
- Address : 44128 Emmerich Brooks Suite 203 Lake Justus, VT 20972
- Phone : +13527031731
- Company : Sauer-Fay
- Job : Engineering Teacher
- Bio : Animi sunt eligendi sit dolor dolorem. Est cum voluptas a aut ex. Officia id rerum qui est occaecati et quis.
Socials
linkedin:
- url : https://linkedin.com/in/cheyenne_bogan
- username : cheyenne_bogan
- bio : Ab qui neque hic suscipit omnis quis itaque eos.
- followers : 3338
- following : 712
facebook:
- url : https://facebook.com/cheyennebogan
- username : cheyennebogan
- bio : Id qui rem laudantium quia. Commodi excepturi exercitationem repudiandae.
- followers : 2427
- following : 2755
tiktok:
- url : https://tiktok.com/@boganc
- username : boganc
- bio : Nostrum dolorum velit totam. Aut omnis sed qui unde.
- followers : 4627
- following : 1933

{kind=link}